Fiche : Protection de votre siteObjet de la fiche :État de la fiche
|



| Test d'accès à un document qui n'existe pas |
|
Télécharger mon fichier .htaccess racine (1)

Protection contre la lecture et le téléchargement de vos répertoires: Fichier .htaccess 1
Si vous rajoutez la ligne suivante au fichier .htaccess du répertoire racine ou dans un répertoire spécifique vous allez protéger votre site contre la lecture et le téléchargement du répertoire ou se trouve le fichier .htaccess. Tous les sous répertoires seront automatiquement eux aussi protégés.
# Accés interdit en consultations des répertoires #
Options -Indexes
Autorisation d'accès à vos pages web Fichiers .htaccess
2 , 3
La restriction d’accès par mot de passe
Dans le cadre des hébergements sur serveur Apache, il est aisé de soustraire
certains répertoires à la curiosité du public.
Le mode opératoire en est simple et s’appuie sur 2 fichiers : le fichiers .htaccess
et un deuxième fichier qui
contiendra les noms et mots de passe des personnes autorisées à accéder au
contenu du répertoire.
Le contenu du fichier .htaccess, est le suivant :
AuthFile MDP/TblU_Tutos.txt
AuthGroupFile /dev/null
AuthName "Accés réservé à des utilisateurs référencés"
AuthType Basic
<Limit GET POST>
require valid-user
</Limit>
Analysons de plus près ces quelques lignes :
AuthUserFile
Donne le répertoire dans lequel se trouve le fichier contenant les paires
login/mot de passe des visiteurs autorisés. Il s'agit du chemin d’accès depuis la racine du serveur.
AuthGroupFile /dev/null
Permet de donner un droit d’accès à un ensemble d’utilisateurs faisant partie d’un même groupe et est rarement utilisée dans le cas de sites Web personnels. Dans l’exemple, le fichier « /dev/null » est l’équivalent Unix de « nulle-part » ou « pas de fichier spécifique »
AuthName "Accés réservé à des utilisateurs référencés"
Chaîne de caractère qui apparaîtra dans la boîte de dialogue au moment de la saisie du nom et du mot de passe.
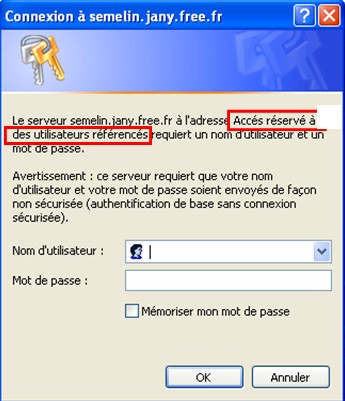
AuthType Basic
Détermine le type d’authentification utilisé, dans notre cas l’authentification HTTP standard.
<limit GET POST> ... </limit>
Détermine le type d’opérations permises. GET s’applique à la majorité des pages Web, PUT est utilisé par certains scripts ou éditeurs pour faire de l’upload sous protocole http. Il est important de mettre GET et POST en majuscule sur les dernières versions d’Apache.
require valid-user
Signifie littéralement qu’un utilisateur valide est requis, à savoir un
utilisateur pour le nom duquel une ligne existe dans le fichier des login et mot
de passe. Une variante pourrait être :
require user pierre paul
pour limiter l’accès aux seuls utilisateurs pierre et paul.
Le fichier des login et mot de passe : Fichiers .htaccess
4
Pour chaque utilisateur autorisé ce fichier texte, dont le répertoire et le nom sont précisés dans le paramètre AuthFile décrit précédemment, contient sur chacune des ses lignes le nom de chaque utilisateur suivi des deux points (:), puis du mot de passe crypté (solution recommandée) ou en clair. Le cryptage.
Cela donne par exemple :
Pierre:motdepassepierre
Lucien:motdepasselucien
# Hector:motdepassehector en cryptage#
Hector:$1$f5hFQAaE$O2ywpRG/2eUoAiazqQNJ71
Attention : chez certains hébergeur comme free, le cryptage des mots de passe n'est pas pris en compte.
Voici un formulaire ci-dessous afin de crypter votre mot de passe pour
ensuite l'utiliser dans votre fichier .htaccess. Ce cryptage ne convient
pas pour tous les usages. Si par exemple vous voulez crypter un mot de passe en
MD5 ou générer un mot de passe aléatoire, utilisez les rubriques adaptées...
Protéger le fichier des login et mot de passe Fichiers .htaccess 5
Afin d'interdire à un malveillant de lire ces fichier de mots de
passe, il est important d'interdire leur accès en lecture.
La méthode la plus simple consiste à toujours placer les fichier des mots de
passe dans un répertoire, interdit à toute visite avec un nouveau fichier .htaccess placé dans ce
même répertoire.
Un fichier .htaccess réalisant cette interdiction est renseigné comme suit :
deny from all
Déplacement de pages, répertoires, site
Il est parfois nécessaire de déplacer certaines pages ou répertoires d’un site
dans l’optique d’une restructuration. Ceci ne va pas sans poser quelques
problèmes inhérents au changement d’adresse : la page n’est plus accessible pour
les visiteurs qui l’ont mise dans leurs favoris et
les références à cette page dans les moteurs de recherche et annuaires pointent
vers l’ancienne adresse.
Dans ces deux cas de figure, plutôt que de présenter une page d’erreur
personnalisée au visiteur, il est beaucoup plus élégant de le rediriger
automatiquement vers la nouvelle adresse. Ici encore, le fichier .htaccess
est très indiqué.
![]() C'est tout de même
le genre de truc à éviter fortement si on veut s'y retrouver! . Tout de même
cela peut s'avérer utile lorsque l'on désire muter l'ensemble du site d'un
hébergeur vers un nouvel hébergeur.
C'est tout de même
le genre de truc à éviter fortement si on veut s'y retrouver! . Tout de même
cela peut s'avérer utile lorsque l'on désire muter l'ensemble du site d'un
hébergeur vers un nouvel hébergeur.
Déplacer une page :
RedirectPermanent ancien.html http://www.domaine.tld/nouveau.html
Cette directive signale au navigateur que la page ancien.html a été renommée
nouveau.html et renvoie l’entête correcte au navigateur pour signaler ce fait
(entête 301 "déplacement permanent"). L’avantage de cette approche est que les
robots d’indexation des différents moteurs apprendront que cette page a été
déplacée et modifieront leur index pour refléter la nouvelle adresse.
Déplacer un répertoire :
RedirectPermanent /ancien http://www.domaine.tld/nouveau/
Nota : Dans ces 2 cas d’utilisation de la directive RedirectPermanent, la nouvelle adresse de page ou de répertoire doit être une
URL complète.
Changer de nom de domaine (site) :
RedirectPermanent / http://www.nouveaudomaine.tld/
redirigera la racine de l’ancien site vers le nouveau site.
Note : Seuls les moteurs de recherche ajusteront leur index pour refléter la
nouvelle adresse. N’oubliez pas de demander aux annuaires de modifier leurs
liens vers vos pages.
Empêcher l'accès à fichier particulier
Par défaut, Apache applique les restrictions du fichier .htaccess à l'ensemble
des fichiers du répertoire dans lequel il se trouve ainsi qu'à tous les fichiers
contenus dans ses sous-répertoires.
Il est également possible de restreindre l'accès pour un ou plusieurs fichiers
du répertoire grâce à la balise <Files>.
Voici un exemple de restriction aux fichiers admin.php3 et admin2.php3 :
<Files admin.php3>
AuthUserFile /repertoire/de/votre/fichier/.FichierDeMotDePasse
AuthGroupFile /dev/null
AuthName "Accès sécurisé au site CCM"
AuthType Basic
<LIMIT GET POST>
require user JFPillou
</LIMIT>
</Files>
<Files admin2.php3>
AuthUserFile /repertoire/de/votre/fichier/.FichierDeMotDePasse
AuthGroupFile /dev/null
AuthName "Accès sécurisé au site CCM"
AuthType Basic
<LIMIT GET POST>
require user JFPillou
</LIMIT>
</Files>
Récupérer les informations de login et password au niveau de la page php
Si vous avez protégé un dossier de votre site en utilisant un fichier .htaccess et que vous souhaitez récupérer dans vos pages PHP le login et le mot de passe que l'utilisateur a saisis, il vous suffit d'utiliser ces variables :
$_SERVER['PHP_AUTH_USER'] pour le login
$_SERVER['PHP_AUTH_PW'] // pour le mot de passe Cependant, elles ne fonctionnent qu'avec PHP 5. Avec une version antérieure de PHP (4), seul le login est récupérable, par la variable : $REMOTE_USER
Le fichier Robots.txt
Sur un site on essaye, dans la mesure du possible, de
faire en sorte que les pages soient indexées au mieux par les robots
(spiders) des moteurs de recherche. Mais il peut également arriver
que certaines pages soient confidentielles, ou en tout cas que l'objectif ne soit pas de les diffuser largement sur lesdits moteurs. Un site
ou une page en construction, par exemple, ne doivent pas obligatoirement
être la cible d'une telle aspiration. Il faut alors empêcher certains
spiders de les prendre en compte.
Cela se fait au moyen d'un fichier texte, appelé robots.txt, présent
sur votre serveur. Ce fichier va donner des indications au spider du
moteur sur ce qu'il peut faire et ce qu'il ne doit pas faire sur le site.
Dès que le spider d'un moteur arrive sur un site (par exemple,
http://www.monsite.com/), il va rechercher le
document présent à l'adresse http://www.monsite.com/robots.txt
avant d'effectuer la moindre "aspiration de document". Si ce fichier existe,
il le lit et suit les indications qui y sont inscrites. S'il ne le trouve
pas, il commence son travail de lecture et de sauvegarde de la page HTML
qu'il est venu visiter, considérant qu'a priori rien ne lui est interdit.
Il ne peut exister qu'un seul fichier robots.txt sur un site, et il doit se
trouver au niveau de la racine, comme le montre l'exemple d'adresse
ci-dessus. Le nom du fichier (robots.txt) doit toujours être créé en
minuscules. La structure d'un fichier robots.txt est la suivante :
- User-agent: *
- Disallow: /cgi-bin/
- Disallow: /tempo/
- Disallow: /perso/
- Disallow: /entravaux/
- Disallow: /abonnes/prix.html
Dans cet exemple :
- User-agent: * signifie que l'accès est accordé à tous les agents (tous les spiders), quels qu'ils soient.
-
Le robot n'ira pas explorer les répertoires /cgi-bin/, /tempo/, /perso/ et /entravaux/ du serveur ni le fichier /abonnes/prix.html.
Le répertoire /tempo/, par exemple, correspond à l'adresse http://www.monsite.com/tempo/. Chaque répertoire à exclure de l'aspiration du spider doit faire l'objet d'une ligne Disallow: spécifique. La commande Disallow: permet d'indiquer que "tout ce qui commence par" l'expression indiquée ne doit pas être indexé.
Ainsi :
Disallow: /perso ne
permettra l'indexation ni de http://www.monsite.com/perso/index.html,
ni de http://www.monsite.com/perso.html
Disallow: /perso/
n'indexera pas http://www.monsite.com/perso/index.html,
mais ne s'appliquera pas à l'adresse http://www.monsite.com/perso.html
D'autre part, le fichier robots.txt ne doit pas contenir de lignes vierges
(blanches).
L'étoile (*) n'est acceptée que dans le champ
User-agent.
Elle ne peut servir de joker (ou d'opérateur de troncature) comme
dans l'exemple : Disallow: /entravaux/*.
Il n'existe pas de champ correspondant à la permission, de type
Allow:.
Enfin, le champ de description (User-agent,
Disallow) peut être indifféremment saisi en minuscules ou en
majuscules.
Les lignes qui commencent par un signe dièse (#), ou plus exactement tout ce
qui se trouve à droite de ce signe sur une ligne, est considéré comme étant
un commentaire.
Voici quelques commandes et très classiques importantes du fichier
robots.txt :
| Disallow:/ | Permet d'exclure toutes les pages du serveur (aucune aspiration possible). |
| Disallow: | Permet de n'exclure aucune page du serveur (aucune contrainte). Un fichier robots.txt vide ou inexistant aura une conséquence identique. |
| User-Agent : fast | Permet d'identifier un robot particulier (ici, celui des moteur Lycos et Fast/Alltheweb). |
|
User-agent:fast Disallow: User-agent: * Disallow:/ |
Permet au spider d'Alltheweb et de Lycos (dont l'index est également fourni par Fast) de tout aspirer, mais refuse les autres robots. |
Vous avez également une autre possibilité pour interdire aux spiders des moteurs l'accès à vos pages : la balise Meta Robots. Un autre article sur ce site décrit de façon très précise leur emploi.
|
Autres sources d'information sur le fichier Robots.txt : Un autre article sur la syntaxe de ce fichier : http://www.searchtools.com/robots/robots-txt.html Un vérificateur de syntaxe pour votre fichier robots.txt : http://www.searchengineworld.com/cgi-bin/robotcheck.cgi |
Application au projet de site web